
Reinforcement Learning (RL) has emerged as a powerful paradigm in artificial intelligence, enabling agents to learn optimal behaviors through interactions with environments. Within this domain, one algorithm stands out for its efficiency and effectiveness – Advantage Actor-Critic (A2C). A2C has garnered significant attention for its ability to strike a balance between exploration and exploitation, making it a cornerstone in the advancement of RL. In this article, we delve into the workings of A2C, exploring its key components, strengths, and applications in various domains.
Understanding A2C:
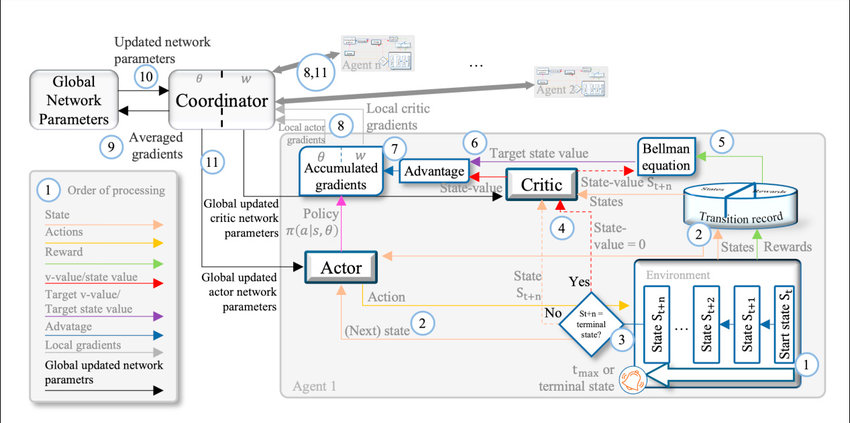
At its core, A2C combines the strengths of two RL approaches: Actor-Critic and Advantage Learning. The Actor-Critic architecture comprises two distinct components: the actor, responsible for decision-making, and the critic, which evaluates the decisions made by the actor. Unlike other RL algorithms, A2C calculates the advantage function, representing the difference between the observed and expected rewards, to guide the learning process more effectively.
Key Components of A2C:
- Actor Network: The actor network is responsible for selecting actions based on the current state of the environment. It learns a policy that maps states to actions, aiming to maximize expected rewards over time.
- Critic Network: The critic network evaluates the actions taken by the actor by estimating the value function. It provides feedback on the quality of actions, helping to refine the policy over successive iterations.
- Advantage Function: The advantage function quantifies the advantage of taking a particular action over others in a given state. It helps the agent to prioritize actions that lead to better-than-expected outcomes, thereby accelerating learning.
Strengths of A2C:
- Efficiency: A2C is computationally efficient compared to other RL algorithms like Q-learning or Deep Q-Networks (DQN). By leveraging parallelization techniques, A2C can update its policy using multiple parallel environments, leading to faster convergence.
- Stability: A2C exhibits greater stability during training, thanks to the advantage function, which reduces the variance in gradient estimates. This stability is crucial for learning in complex environments with sparse rewards.
- Continuous Action Spaces: Unlike some RL algorithms that are limited to discrete action spaces, A2C can handle continuous action spaces effectively, making it suitable for a wide range of real-world applications.
Applications of A2C:
- Robotics: A2C finds applications in robotic control tasks, where agents need to learn complex behaviors in continuous action spaces. It enables robots to navigate environments, manipulate objects, and perform tasks with precision.
- Gaming: A2C has been successfully applied to various video games, surpassing human-level performance in games like Atari and Dota 2. Its ability to handle large action spaces and sparse rewards makes it well-suited for gaming environments.
- Finance: In the domain of finance, A2C is used for portfolio optimization, algorithmic trading, and risk management. It enables agents to make informed decisions in dynamic market environments, maximizing returns while minimizing risks.
Conclusion:
Advantage Actor-Critic (A2C) represents a significant advancement in reinforcement learning, offering a powerful framework for training agents to perform tasks in complex environments. Its ability to balance exploration and exploitation, coupled with efficiency and stability, makes it a preferred choice for researchers and practitioners alike. As advancements in AI continue, A2C is poised to play a pivotal role in shaping the future of autonomous systems across various domains.





